

After the Artificial Intelligence Bubble: What It Is, What It Isn’t, and What It Might Be Good For
What, really, is generative AI, and what is it for? What can we expect to happen to this technology once the hype fully dies down? Will it transform our lives? Will it replace humans?

The original (Spanish) version of this article can be found here.
What has happened with what we call “artificial intelligence” is similar to what happened with other technologies —like Facebook’s Metaverse or Google Glasses—: they were born from companies that had a strong interest in making us believe they would be revolutionary.

Until just a couple of months ago, several of the world’s largest companies were still promising to build an “artificial general intelligence”: a thinking being that would be “superior” to humans and capable of replacing us entirely. In other words, they were announcing the birth of a new species of all-powerful machines that would replace people.
Things got so absurd that at a conference organized by Google that I attended a few months ago, one of the speakers calmly claimed we would need to install a chip in our brains just to keep up with the robots to come. Corporate panic was rampant, and no one was safe.
Some of us have argued for a long time that this was never going to happen. That the very idea of “artificial intelligence” was a scam orchestrated to keep inflating the forward escape of the tech companies, which have had nothing genuinely new to offer for quite some time. Well, in recent weeks the economic and media consensus has fallen from the tree and is arriving at the same conclusion.
“For many companies,” The Economist said a few days ago, “the excitement over the potential of generative artificial intelligence has given way to frustration over the difficulty of using this technology productively.”
Meanwhile, The New York Times, in an article titled “Why Artificial General Intelligence Is Unlikely Anytime Soon”, got to the heart of the matter by quoting Steven Pinker: “there is simply no such thing as an omniscient, omnipotent automatic problem solver for all problems, including those we haven’t even imagined yet. There is a temptation to fall into a kind of magical thinking. But these systems are not miracles. They are very impressive gadgets.”
Reality, stubborn as it is, has imposed itself on the apocalyptic threats, and according to S&P Global, 42% of companies will have abandoned their generative AI pilot projects by 2025.
All that said, we can’t shake the feeling that these little machines that talk as if they really think must be good for something. They’re just too spectacular to amount to nothing, right?
And that is true. The technologies behind chatbots will bring about very significant advances —just not the ones we’ve been told.
So what, really, is generative AI, and what is it for? What can we expect once the hype truly fades? Will it transform our lives? Will it replace humans?
Humans evolved to relate to a very small community. Until the invention of agriculture —that is, for 95% of our species’ history— human groups had between 25 and 50 members. Everyone knew each other intimately.
Anthropologists think that, if there was a broader network linking some groups to others they might encounter occasionally, that network could not exceed 150 individuals, because there is a “cognitive limit” to the number of relationships humans can maintain without additional support.
Our primary methods of understanding the world were direct observation and gossip. Observation allowed us to interact with our immediate environment, and since there was no need to comprehend anything beyond what could be seen and touched, that was sufficient.
Gossip, on the other hand, was the mechanism for understanding other humans. “Social cooperation is our key to survival and reproduction,” says Yuval Harari. “It is not enough for men and women to know the whereabouts of lions and bison; it is far more important for them to know who hates whom in their group, who is sleeping with whom, who is honest, and who cannot be trusted.”
When we moved from hunter-gatherers to the first agricultural settlements, it became necessary to understand realities we could not observe directly. Gossip and observation became insufficient, and new technologies were born to help us understand and manage the growing complexity of society. That is why agriculture is inseparable from the emergence of writing and numerical and mathematical systems.
Those two technologies were nothing more than an interface that allowed us to relate to a far more complex reality than our brains could handle on their own. Writing gave us access to stories and ideas from people we did not know and who could be very far away —in time and in space. Mathematics, meanwhile, created abstractions in which to store information about large groups, such as records, accounting, or statistics.
As societies became more complex, those “interfaces” between the human mind and complexity kept improving: books, painting, printing, the first property or birth registries, libraries, encyclopedias, abacuses, calculators, cash registers, universities, and administrative centers appeared —all to bring order and meaning to the world.
Eventually, we became capable of understanding entire realities even if we had never had direct contact with them: television, photography, history, literature, statistics, and the media, among many other things, made us see ourselves as part of an immense social group spanning seven continents and thousands of years.
The first computers were born to respond to that growing complexity. The amount of information we were using in the 1980s was becoming unmanageable without computing. Paper records, which could only be “computed” by hand —adding and subtracting— had become a bottleneck for progress.
That is why computing created an exponential leap in the human capacity to relate to complexity. Machines can store millions of times more information than a book and retrieve the part we need far faster than it would take to leaf through a massive collection of records.
But to achieve that, they had to make a concession: that information would no longer be organized for human understanding —which was still designed around observation and gossip— but rather for the machine. Let’s look at an example:
Think of a grocery store. This is the kind of record a person would make of their sales, based on observation and knowledge of each customer:

A computer would never organize information this way, mixing first names, last names, different product types, and notes, because these are actually very different things that only make sense relationally in our human heads.
Instead, it would create several tables:
One for customers,
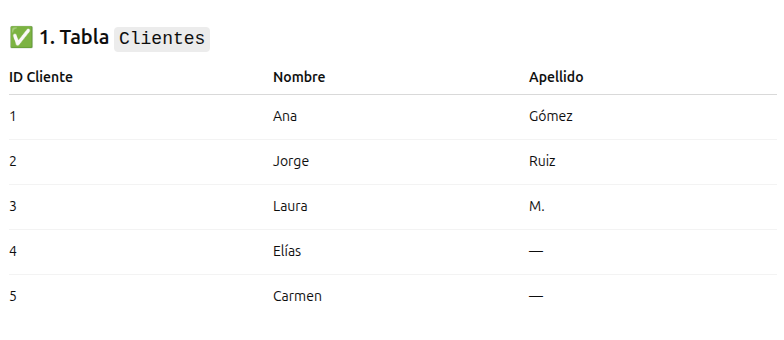
Another for product types

And another for each main record, linking the other tables through a numeric identifier

The result is a far more efficient, better-organized system, capable of managing information and producing reports on demand —but incomprehensible to the human mind.
Then came the Internet. The amount of information created by humanity exploded like a supernova. In 1993, the entire web generated barely 40,000 GB per year; today we produce over 120 zettabytes —30 million times more. Every minute more than 500 hours of video are uploaded to YouTube, 40 million WhatsApp messages are sent, and more than 6 million searches are made on Google. We have gone from storing knowledge in books and physical archives to producing data massively in real time, on a scale never seen before in human history.
And all that knowledge is not stored in a format adapted to our minds, but to machines: it is inaccessible to humans. That’s why we have such a massive sense of not understanding anything: because it’s true, there is simply too much information, and we lack the interfaces to process it.
And all of this has happened at record speed: it is estimated that more than 90% of existing digital data was generated in the past 10 years, and the total volume of information DOUBLES every 12 months. In fields like medicine, knowledge doubles every 73 days.
As if we were hunter-gatherers teleported to present-day New York City, we do not have the tools to comprehend all this information, this level of complexity. That’s why we cannot make sense of what happens on social media, and we feel overwhelmed by the information we receive.
AI as an Interface Between Human Knowledge and Machine Knowledge
The very first attempts to solve this problem and give us an interface to access this massive repository of knowledge were Google search, initially, and later mechanisms like “trending topics” and hashtags on social networks.
Both are information-access tools. Some let you search the entire internet and return results, while others show you the topics many people are talking about at the same time. But they all have the same limitation: they are still designed —and limited— by the human mind. They still try to understand a flow of information that is not organized according to our logic from our way of thinking.
The giant leap of AI is that someone came up with the idea just a few years ago that it should not be humans designing the interfaces to access information, but the machines themselves.
The idea behind machine learning and generative AI is the transformer: a type of system that learns to understand patterns and relationships within enormous volumes of data, especially language. How does it learn? It is fed millions of questions along with their correct answers, and the system tries to guess the answer by adjusting a network of internal connections called “weights.” At first, it fails almost every time. But each time it makes a mistake, it tweaks those weights a bit. And so, mistake after mistake, it learns to arrive at the correct answer on its own. The surprising thing about the transformer is that it does not follow a fixed path: it figures out on its own how to pay attention to the most relevant parts of each sentence or data set to find meaning.
This way, it is the machines that learn how to access information and how to display it, without us having to tell them step by step how to do it. And the thing is, they do it much better than we ever could, because that volume of information is made for them, not for us.
Confusion emerges when we give these chatbots the appearance of people with consciousness: we associate talking to them with the experience of talking to an expert, when they are not.
For example, if I ask a chatbot “what do you think about very short bangs?” it will give me a terribly mediocre answer full of clichés. Since it has no consciousness —no style, no taste— it cannot have opinions about bangs, or anything else.
When I ask a chatbot about bangs, expecting a human-like answer, it gives me the statistically most likely answer: that of the average human, which is to say, mediocre. That’s why sometimes it makes things up, often bores me, and always leaves me a bit cold.
But if, instead of thinking of them that way, we imagine we are talking to our computer and want to use its intelligence to access the content of all that information available on the internet, they become truly useful. For example, I might ask my computer “What has been said on the internet in the past 5 years about very short bangs?” or “What do people in Japan think about bangs?” or “What did people think about bangs between 1990 and 2010?” In this sense, they are a version 2.0 of what powers search engines.
Machines cannot access the truth, because truth is a concept that comes from consciousness. But they can open the door for us to a new level of human knowledge that we will never be able to reach without their help.
What opportunities will this new era bring?